When Google and other search engines index websites, they don’t execute JavaScript. This seems to put Single Page Application (SPA) — many of which rely on JavaScript — at a tremendous disadvantage compared to a traditional website.
If you’re running a SPA with content that you’d like to appear in search results of Google and other search engines websites, then you have to index your content. Historically, AJAX applications have been difficult for search engines to process because AJAX content is produced dynamically by the browser and thus not visible to crawlers because they cannot execute JavaScript. The browsers can run JavaScript and create content on the fly – the search crawler cannot. To make the crawler see what a user sees, the server needs to give a crawler an HTML snapshot, the result of executing the JavaScript on your page. HTML snapshot allows the web server to return to the crawler this HTML created from static content pieces as well as by executing JavaScript for the application’s pages.
Solution:
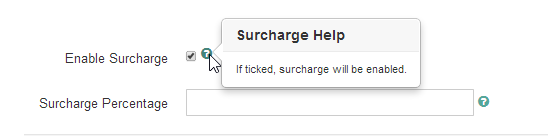
Here is an image made by Google depicting the setup of how a crawler index AJAX crawling scheme enable application using HTML snapshot and improve Search Engine Optimization (SEO).
")
Ajax Crawler Diagram (Graphic by Katharina Probst)
In your SPA replaces the hash fragments (e.g. #myForm) to hashbang (e.g. #!myForm).
For example, replace
www.example.com/index.html#myForm
to
www.example.com/index.html#!myForm (which could be available to both crawlers and users.)
How do we create different hash bang for various contents in the same URL of a SPA?
If you are using KnockoutJS, you might use SammyJS or PagerJS to support hash fragments. See http://stackoverflow.com/a/9707671/798727 for how to use it.
If you are using AngularJS, the ngRoute module is available in the framework itself. See http://stackoverflow.com/a/16678065/798727 for how to use it.
When the crawler see the hashbang (#!), it knows that the site supports AJAX crawling scheme on its web server. You have to provide the crawler with an HTML snapshot of this URL so that the crawler sees the content. How will your server know when to return an HTML snapshot instead of a regular page? The answer is the URL that is requested by the crawler: the crawler will modify each AJAX URL such as
www.example.com/index.html#!myForm
to
www.example.com/index.html?_escaped_fragment_=myForm
There are two critical reasons why hash bang is necessary:
- Hash fragments are never (by specification) sent to the server as part of an HTTP request. In other words, the crawler needs some way to let your server know that it wants the content for the URL
www.example.com/index.html#!myForm (as opposed to simply www.example.com/index.html).
- Your server, on the other hand, needs to know that it has to return an HTML snapshot, rather than the standard page sent to the browser. An HTML snapshot is all the content that appears on the page after the JavaScript has been executed. Your web server returns the HTML snapshot for
www.example.com/index.html#!myForm (that is, the original URL!) to the crawler.
When the crawler sees the hash bang it to replace it with the “_escaped_fragment_” before making the request to the web server to index that page. For example
www.example.com/index.html?_escaped_fragment_=myForm.
The web server sees the “_escaped_fragment_” in the URL it knows that the request is from a crawler. The web server will then redirect the request to the headless browser to serve HTML snapshot from the server.
How to create HTML snapshots on the web server?
If you are a .NET developers you could use ASP.NET MVC with PhantomJS. Create an [AjaxCrawlableAttribute] which will redirect all request with “_escaped_fragment_” in the query string to the HtmlSnapshotController. The HtmlSnapshotController will load the PhantomJS.exe to create HTML snapshot. You can get the PhantomJSexe in the Nuget gallery. Please see this article for detail implementation steps http://stackoverflow.com/a/18530259/798727.
If you do not want these headache of creating, maintaining & scaling HTML snapshot on your web server check out the following online SaaS,
- Brombone is using nodejs, PhantomJS, Amazon AWS SQS, AWS EC2, and AWS S3. BromBone supports sites that use HTML5 pushState URLs instead of hashbang URLs. They do not offer a free trial plan, but they offer a no questions ask money back guarantee. If you have any question contact Chad DeShon (Founder of Brombone) on Chad@brombone.com. Check them on out http://www.brombone.com.
- AjaxSnapshots has multiple snapshotting servers on Amazon AWS, which has a Java based dispatcher that sends requests on to one of the PhantomJS based headless servers. They use Amazon AWS SQS, AWS EC2, AWS ELB for load balancing and AWS S3. They got a free trial plan. They also claim that PhantomJS script that they run benefits from many modifications they have made to deal with corner cases that trip up naive implementations. If you have any question contact Robert Dunne (Founder of AjaxSnapshots) on support@ajaxsnapshots.com. Robert also wrote a helpful summary of which search and social bots are aware http://blog.ajaxsnapshots.com/2013/11/googles-crawlable-ajax-specification.html. Check them out on https://ajaxsnapshots.com.
How to test headless browser content?
It’s highly recommended that you try out your HTML snapshot mechanism. It’s important to make sure that the headless browser indeed renders the content of your application’s state correctly. Surely you’ll want to know what the crawler will see, right? To do this, you can write a small test application and see the output, or you can use a tool such as Fetch as Googlebot. A .NET developers could use NHtmlUnit. NHtmlUnit is a .NET wrapper of HtmlUnit; a “GUI-less browser for Java programs”. It allows you to write code to test web applications with a headless, automated browser.
Google put the following steps to make your SPA crawling,
- Indicate to the crawler that your site supports the AJAX crawling scheme.
- Set up your server to handle requests for URLs that contain
- Handle pages without hash fragments
- Consider updating your Sitemap to list the new AJAX URLs
To see the details implementation of the above steps click Guide to AJAX crawling for webmasters and developers. You might find Making AJAX Applications Crawlable useful too.
Summary
In summary, starting with a stateful URL such as http://www.example.com/index.html#myForm , it could be available to both crawlers and users as http://www.example.com/index.html#!myForm which could be crawled as Using modern headless browsers, we can easily return the fully rendered content per request by redirecting bots on web servers.
References
In 2009, Google released the idea of escaped fragments.
http://www.singlepageapplicationseo.com
http://www.branded3.com/blogs/javascript-back-buttons-seo-dont-mix
http://diveintohtml5.info/examples/history/fer.html)
http://googlewebmastercentral.blogspot.com.au/2009/10/proposal-for-making-ajax-crawlable.html http://stackoverflow.com/questions/18530258/how-to-make-a-spa-seo-crawlable
https://developers.google.com/webmasters/ajax-crawling Services
http://www.brombone.com/
https://ajaxsnapshots.com/configGuide#Tellingsearchenginesyouprovidesnapshots
https://github.com/prerender/prerender
Reviewers
Special thanks to Chad DeShon (Founder of Brombone) and Robert Dunne (Founder of AjaxSnapshots) for reviewing this blog.
-33.867139
151.207114
")




 certificate")
 certificate")
